Given an audio-visual pair, audio-visual segmentation (AVS) aims to locate sounding sources by predicting pixel-wise maps.
Previous methods assume that each sound component in an audio signal always has a visual counterpart in the image.
However, this assumption overlooks that off-screen sounds and background noise often contaminate the audio recordings in real-world scenarios.
They impose significant challenges on building a consistent semantic mapping between audio and visual signals for AVS models and thus impede precise sound localization.
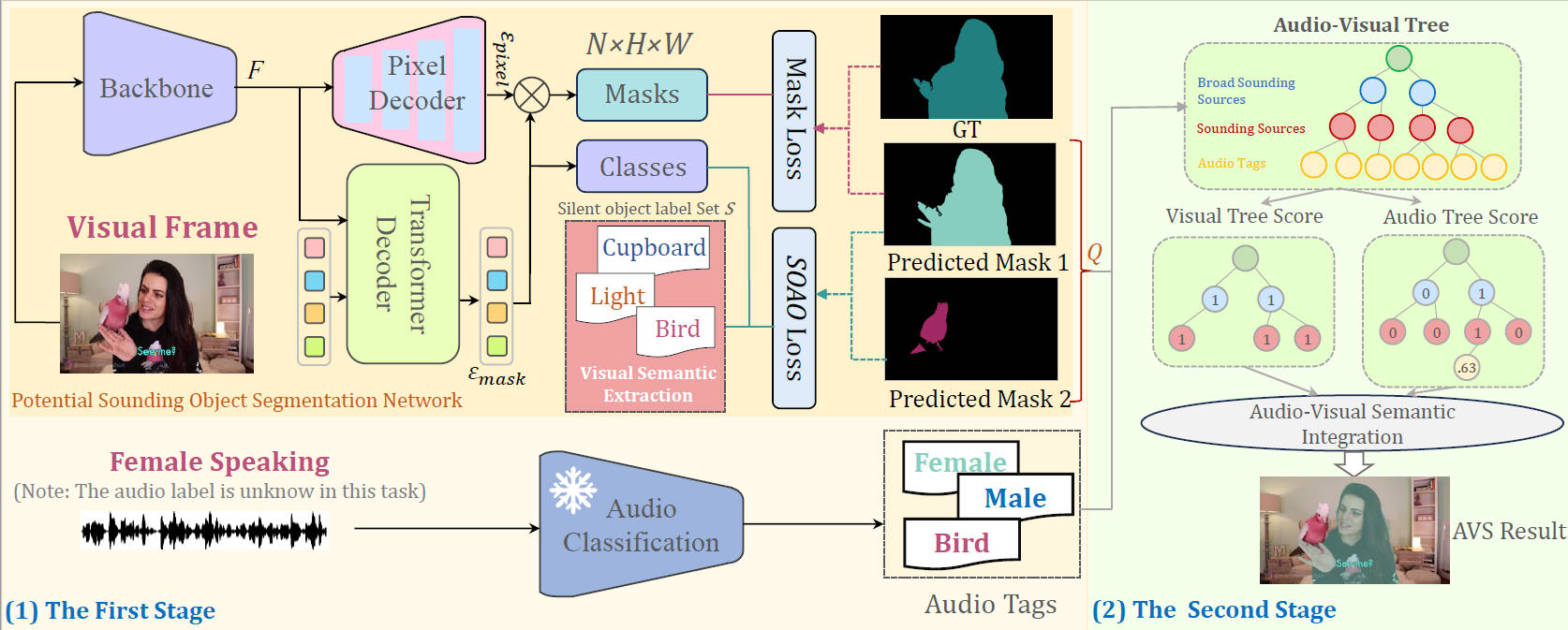
In this work, we propose a two-stage bootstrapping audio-visual segmentation framework by incorporating multi-modal foundation knowledge.
In a nutshell, our BAVS is designed to eliminate the interference of background noise or off-screen sounds in segmentation by establishing the audio-visual correspondences in an explicit manner.
In the first stage, we employ a segmentation model to localize potential sounding objects from visual data without being affected by contaminated audio signals.
In the meanwhile, we also utilize a foundation audio classification model to discern audio semantics.
Considering the audio tags provided by the audio foundation model are noisy, associating object masks with audio tags is not trivial.
In the second stage, we develop an audio-visual semantic integration strategy (AVIS) to localize the authentic-sounding objects.
Here, we construct an audio-visual tree based on the hierarchical correspondence between sounds and object categories. Then, we examine the label concurrency between the localized objects and classified audio tags by tracing the audio-visual tree.
With AVIS, we can effectively segment real-sounding objects.
Extensive experiments demonstrate the superiority of our method on AVS datasets, particularly in scenarios involving background noise.